
Amino acids
Absolute configuration at the position
Understanding the absolute configuration of amino acids is essential for describing their stereochemical behavior in protein structures and biochemical reactions.
Absolute configuration tells you the exact three-dimensional arrangement of substituents around a chiral center - usually the alpha () carbon in an amino acid. To assign an R or S configuration, chemists apply the Cahn-Ingold-Prelog (CIP) priority rules to rank the four groups attached to the carbon.
So, the carbon is bonded to an amino group, a carboxyl group, a hydrogen atom, and a variable side chain (R). After you assign priorities to these four groups, you look at their 3D orientation around the chiral center to determine whether the configuration is R (“rectus”) or S (“sinister”).
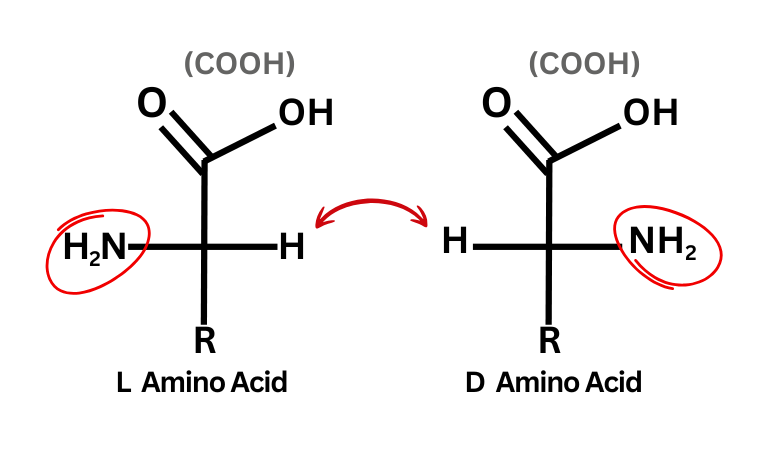
The R/S label depends only on this spatial arrangement. It’s separate from D/L notation, which is based on how a molecule’s projection compares to glyceraldehyde. Biologically, most naturally occurring amino acids are the L form, and nearly all of those are S by CIP rules.
Two important exceptions are:
- Glycine, which is achiral because its side chain is a second hydrogen.
- Cysteine, which is typically R because its sulfur-containing side chain changes the CIP priority order.
Case 1: Priority of
For most amino acids, the substituent ranking is:
- (highest)
- (lowest)
To assign R or S, you view the molecule with the lowest-priority group (H) pointing away from you. With this ranking, the biologically common L form typically corresponds to an S absolute configuration. Consequently:
- L = S
- D = R
Example:
- L-alanine normally ends up being S-alanine under CIP rules.
In alanine, the amino group has higher priority than the carboxyl group, and the carboxyl group has higher priority than the methyl side chain. With H oriented away, the resulting 3D arrangement for the L enantiomer is S.
Case 2: Priority of
For cysteine, the sulfur-containing side chain outranks the carboxyl group under CIP rules because sulfur has a higher atomic number than oxygen. The priorities become:
- (highest)
- (the sulfur-containing side chain)
- (lowest)
With this ordering, applying the CIP rules gives the L enantiomer an R configuration instead of S. So:
- L = R
- D = S
Example:
- L-cysteine turns out to be R-cysteine.
This happens because sulfur raises the side chain’s priority above the carboxyl group. So even though cysteine is still classified as L (relative to L-glyceraldehyde), its absolute configuration is R.
Why L vs. D does not always match S vs. R
- L / D notation refers to how the molecule aligns with the reference standard of glyceraldehyde and does not depend on CIP atomic-number priorities.
- S / R notation depends only on substituent ranking around the chiral center using the Cahn-Ingold-Prelog rules.
In most amino acids, the L form corresponds to the S configuration (Case 1). Cysteine (Case 2) is the classic exception: the L form is R by CIP rules because the sulfur-containing side chain has higher priority.
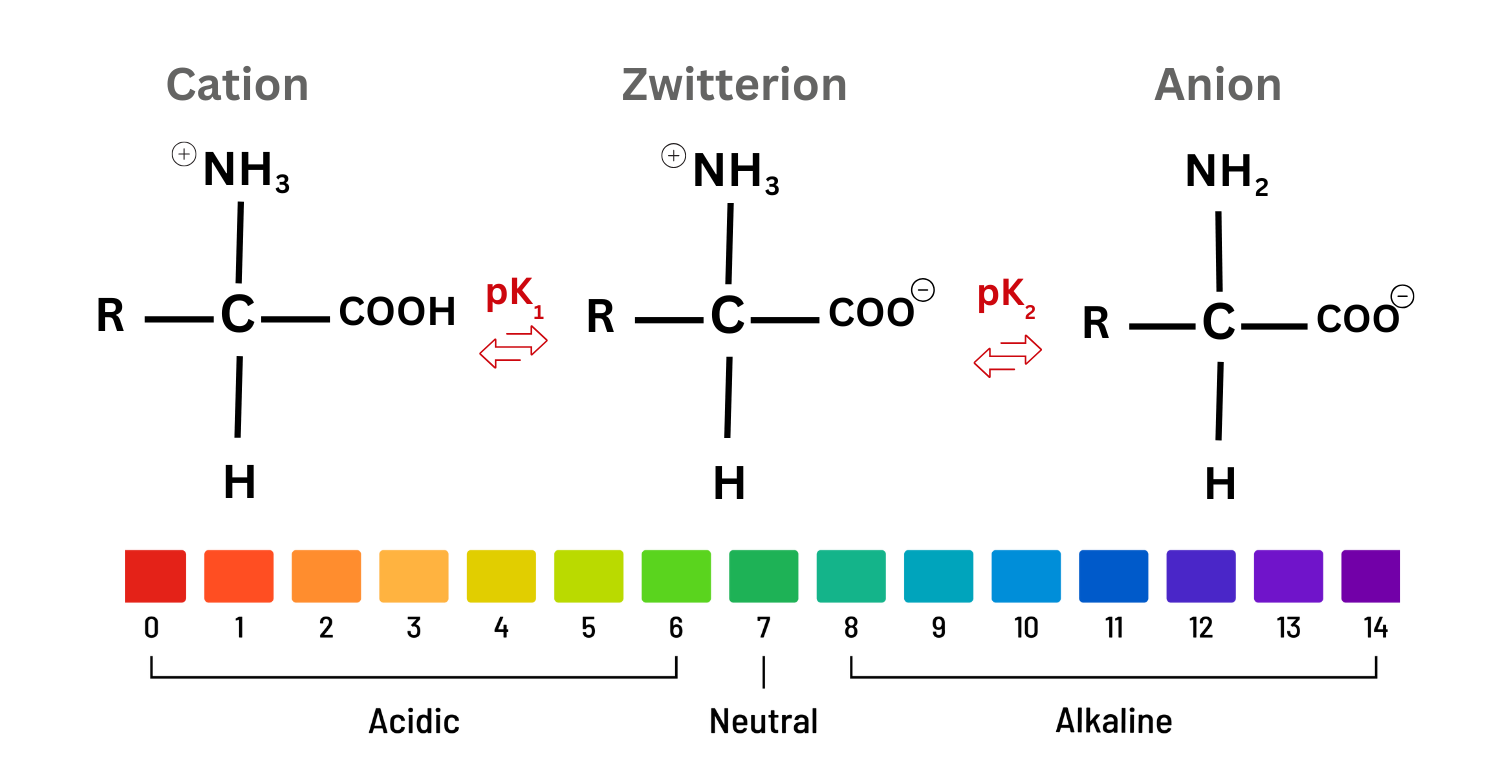
Amino acids as dipolar ions
Amino acids can exist as dipolar ions, also called zwitterions, because a single molecule can carry both a positive and a negative charge under typical physiological conditions. An amino acid contains an amino group (-) and a carboxyl group (-). In an acidic environment, the amino group can gain a proton to become -⁺, while the carboxyl group can donate a proton to become -.
That means the molecule can simultaneously contain:
- a positively charged group (on nitrogen)
- a negatively charged group (on oxygen)
This charge pattern affects how amino acids:
- dissolve
- interact with charged molecules
- fold into larger proteins.
The exact pH at which an amino acid predominantly exists in its dipolar form varies with side-chain properties and the pKa values of its functional groups. In biological systems near neutral pH, most amino acids exist largely in this zwitterionic state, which influences their behavior in water and their binding to enzymes or other biomolecules.
Amino acid classifications
Acidic or basic
- Because amino acids contain both a carboxyl group (-) and an amino group (-), they can act as both acids and bases. In an acidic environment, the amino group can accept a proton to become -. In a more basic setting, the carboxyl group can lose a proton to form -. These reversible proton transfers let amino acids buffer pH changes and show amphoteric behavior.
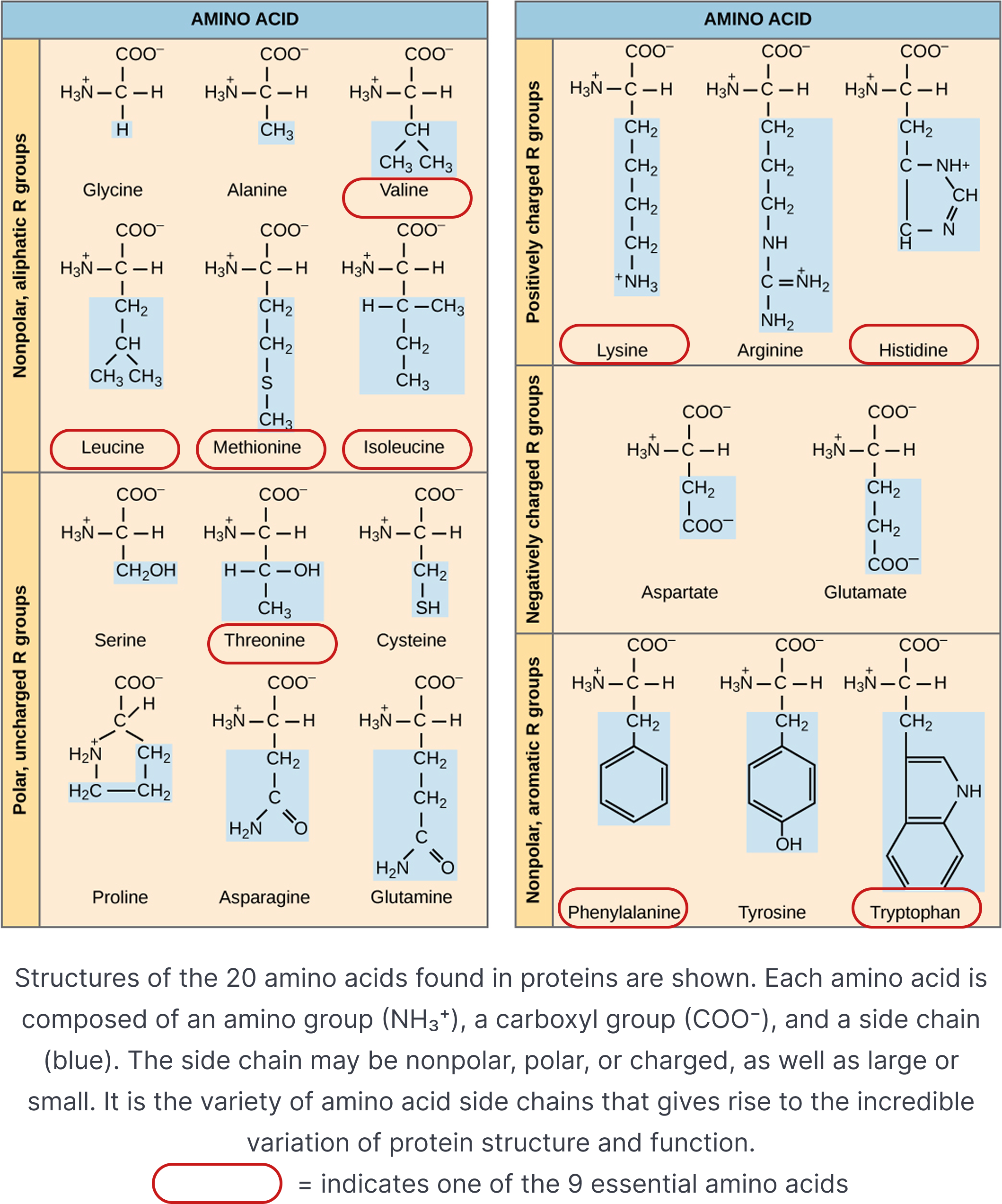
Hydrophobic or hydrophilic
- Amino acids can also be classified by the nature of their side chains, which may be hydrophobic or hydrophilic.
Hydrophobic amino acids typically have nonpolar side chains made mostly of carbon and hydrogen, so they tend to avoid water and interact with other nonpolar surfaces. In contrast, hydrophilic amino acids have polar or charged side chains that readily form hydrogen bonds or electrostatic interactions with water. This difference in side-chain polarity strongly influences:
- how amino acids orient themselves in proteins
- how they cluster or repel each other
- how they shape overall protein folding and function.
Amino acid reactions
Sulfur linkage for cysteine and cystine
- Cysteine, one of the sulfur-containing amino acids, has a thiol group () in its side chain. When two cysteine residues come close together within a polypeptide or between different polypeptide chains, their sulfur atoms can form a disulfide bond, producing cystine. This disulfide linkage () helps stabilize the three-dimensional structure of proteins, supporting overall shape and functional integrity.
Peptide linkage: polypeptides and proteins
- Peptide bonds are central to building chains of amino acids. When the carboxyl end (-) of one amino acid reacts with the amino end (-) of another, a peptide linkage forms and a molecule of water is released. Repeating this condensation reaction joins amino acids into longer chains called polypeptides. Depending on length and complexity, polypeptides may remain relatively short or fold into larger assemblies known as proteins. In proteins, the amino acid sequence (primary structure) and the resulting folding (secondary, tertiary, and sometimes quaternary structures) determine function, stability, and interactions with other molecules.
Hydrolysis
- Hydrolysis of amino acids, in the context of peptide or polypeptide breakdown, means cleaving the peptide bond (the link between the carboxyl group of one amino acid and the amino group of another). This can happen through acid or base treatment in the lab or through enzymes (proteases) in biological systems. In all cases, water participates in breaking the bond, producing shorter segments - such as dipeptides or tripeptides - or ultimately releasing the individual amino acids. In living organisms, this controlled process is essential for protein digestion and turnover, allowing cells to recycle amino acids for new protein synthesis or for energy production.
If we denote a compound as AB, where A and B represent atoms or groups, and water is expressed as HOH, hydrolysis can be represented by the reversible equation: